
Technical Proposal To <<Operator
Name/Logo>> For Managed Services
Table of
Contents
2. MS
Experience with Operator
4.4.5 Configuration
Management
4.5.1 Governance
framework overview
The Purpose
of the document is to define the service deliverables, responsibility matrix,
dependencies and risks between MS and <<Name of Operator>> for
completing the scope.
The scope of
this document is to provide the overview of MS’s Managed VAS proposition and
describe in details those components of solution specific to the technical
requirements of the RFP
Document is
intended for the technical stakeholders of <<Name of Operator>>
involved in the operations and MS MS and Delivery Teams.
MS thanks <<Operator
Name>> for giving us this opportunity to propose our solution for
managing <<Name of
RFP/Scope>> in <Name of
Region>>.
MS through its
large telco heritage has best practices and will be delighted to be a part of <<Operator Name>> growth story. Given our
experience in emerging markets such as India, Asia Pacific, Africa and Middle
East, we believe we could be the right partner for BAL to handle their Application
Managed
Services in Africa.
Today Managed Services vertical
of MS is
currently managing complete IT/VAS
eco-system
of
20+ operators globally, from as low as 4 million
subscribers to 750+ million subscribers. MS continued and fruitful partnership with
operators and healthy collaboration with their ISVs, is a reflection of our ability to deliver
value in managing the services successfully.
To continue
leading and innovating in the Managed Services industry, MS has made continuous
investments especially in People, Tools and Platform.
MS innovative range of products & services
have won several awards from different corners of the world like ‘Golden
Peacock’ award for innovation, ‘Best Product Initiative’ award from Frost &
Sullivan, ‘Best New Service’ award at the AfricaCOM, INFOCOM CMAI National
Telecom Award for Excellence and many more.
MS
Managed Services Solution helps mobile carriers to transform from network
centric to user and service centric operation.
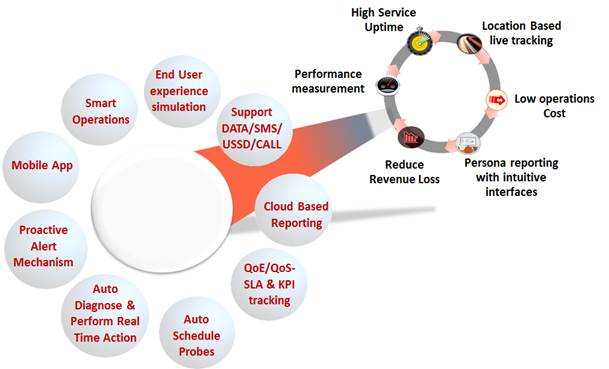
Some key points of our Managed services are:
·
A
proven track record in Managed Services with rich experienced experts. Well-trained and certified personnel with
many years of experience in ITIL®, eTOM, PMP, CISSP & CISA. 10
+ years’ experience in transformation
and transition approaches
MS will leverage its vast Telecom
experience and proposes solution keeping in mind Airtel’s business objectives.
As part of continuous improvement, MS will implement it best practices in terms
of Tools, Techniques, Processes, and Frameworks.
.
<<Name
of Operator>> intends to engage Managed Services partner for VAS
applications ecosystem management with focus on :
MS established in 1999, provides services to
130+ mobile operators across 90+ countries delivering services to over 1
billion subscribers. MS has strong relationship with large operator groups,
such as, Vodafone, Airtel, MTN, Orange (France Telecom) and Etisalat, providing services through group wide
framework agreement to their operating companies worldwide.
Over 12% of global prepaid users recharge
using MS deployed recharge solution. Our m-commerce solution powers financial
services to 800+ million mobile users and merchants across the planet.

MS
managed services practice, started way back in 2007, enables operators to focus
on competitive business objectives leaving technology operational practices to
an expert technical partner. MS MS
ensures SLA / KPI based services delivery with focus on speedy go-to-market,
standard process based service delivery, customer experience and cost
efficiency.
1.
MS-Leader in MS-VAS Practice
o Frist one to conceptualize the MS-VAS
Practice
o End to end cross ISV MS–VAS Practice for
10+ years across Tier1 Opcos in Europe, Africa, Middle East, South Asia and
India
o Experience in Datacenter migration and
VAS Zoning
o Enjoying cordial relationships with more than 90+ ISVs and OEMs including
our competitors for managing their nodes
o Established Security & NOC Center of Excellence
o Developed
in-house tools on performance monitoring, self-healing,
service path monitoring and cognitive analysis
o
Innovation – continuous investments in the VAS
domain helps in better delivery of MS for the VAS platforms. MS can separately
propose technology transformation as desired by VF
2.
Scale of Operations in MS-VAS
o Managing 7000+ VAS nodes and 4000+
network devices across the globe
o Currently managing one of the one
world’s single largest messaging
deployment - SMS Router (SDC)
deployed in Vodafone India
o Running state of the art and dedicated
24x7 GNOC in MS premises to ensure business continuity
3.
Industry Recognition
o  Advisory Board Members of MS World Congress and GSMA MS Forum
Advisory Board Members of MS World Congress and GSMA MS Forum
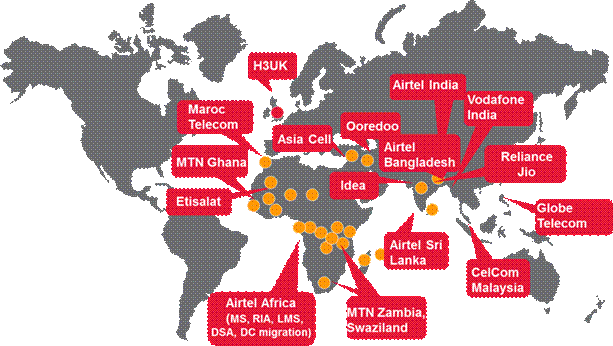
For
case studies please refer Annexure A of this
document.

·
Proven and Trusted Partnership with <<Name of Operator>>
o
Engaged
with <<Name of Operator>> India for more than 18 years, hence,
conversant with <<Name of Operator>>’s infrastructure & ecosystem
o
Existing
Managed Services Provide for SDC
o
Powering
mission critical services e.g. E-Recharge, SMS, Tele verification
o
Known
for its flexibility and agility
o
Integration
experience with almost all version/ OEMs of INs, HLRs and SMSCs, GGSNs, STPs and
MSCs in Vodafone India
o
Many
game changing co-innovations with Vodafone India (refer to section 6)
·
Knowledge and experience in VAS domain
o
Only
Integrated VAS Organization having diverse product offerings and domain
expertise
o
Track
record of complex integration – integration with almost all prepaid INs, HLRs,
mediation server, post-paid billing systems, IT systems, SMSCs, USSD Gateways,
MSCs etc.
o
Unique
combinations of domain expertise on the device side and operator’s
infrastructure
·
Market Leadership in VAS domain
o
Mature
proven products - more than 130+ operator partners across globe
o
Manages
100+ vendors / partners globally
o
1700
+ Employees largest company in VAS domain
o
12%
of world population replenishes recharge through PreTUPS™
o
20%
global recharge transactions market share – 21 Bn Recharges per year
o
20%
global mobile money transactions market share
o
800
Bn Messages Processed last year
o
1.5
Bn call details processed in a day in single deployment
Applications under the scope of this RFP :
Service
delivery scope would entail the following services for both L1 and L2
operations:
|
Mega Bulk gateway |
Welcome handler – Probes |
UCC |
Emergency Alerts for VF employees |
|
NTMS |
Welcom Handler - Central servers |
DSTK |
Etopup 6.X |
|
WAP Gateway |
SPRS |
LBS |
Antispam - SMSR |
|
BMG Bulk Gateway |
SRS |
SMS Hub |
Data optimization |
|
MMSC+MTA |
RTSP |
VHE |
Subscriber Authentication gateway |
|
USSD Gateway |
SCB |
CEM (Customer Experience Management) |
|
The
following services would be considered for L1 operations only:
|
CRBT and Other Services |
Msearch |
Emergency Alerts( for normal customers) |
HLR View |
|
Celltick |
Myraid USSD |
SCL Digital |
CMS |
|
MCI |
Star talk |
Bsmart |
Hunagama IVR |
|
Contakt |
Song Catcher |
Handygo Rural VAS |
Mobile advt |
|
IVR VAS |
Live Astrology |
VF TV |
Altruist(M2W) IVR |
|
V Chat |
Voice SMS/Auto VMS |
IBD&OBD |
|
In line with RFP of Vodafone, following are key functions to
be offered:
·
Managed
Vodafone NOC for VAS - 24 x 7
·
Operations
Management
·
Central
Help desk for complaint resolution
·
Field
Operations for VAS platform
·
Database
Management
·
Inventory
and Spare management.
·
Security
management
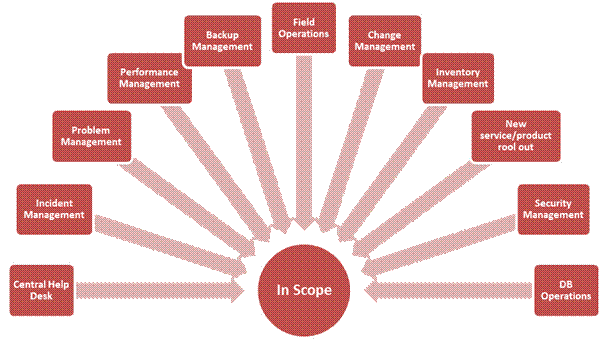
MS
understands the detailed requirements as in following deliverables:
Ø
Fault
and Alarm Management
Ø
1st
Level Operations
Ø
2nd
Level Operations
Ø
Service
& Resource Fulfillment
Ø
Inventory
and Spare Part Management
Ø
Service
and Platform Optimization
Ø
SLA/KPI
Management
Ø
Governance
MS
proven record in operational efficiency by adding value to operators is
depicted below:
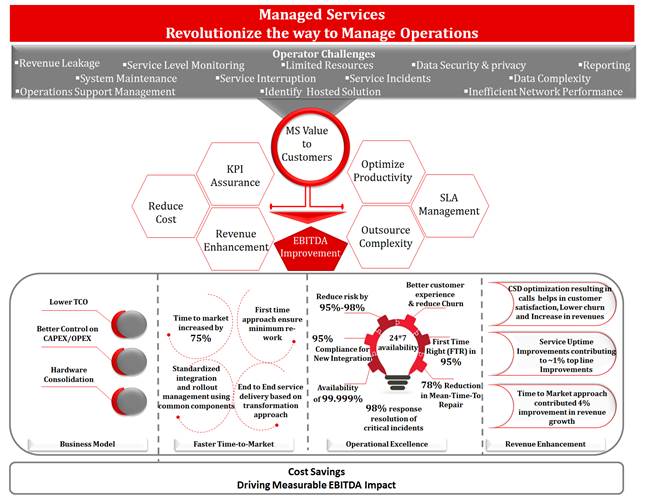 Managing a complex value chain such as
that of VAS can drain the Operator’s resources and they risk deviating from
their core competence. MS Managed Services ensures to reduce the Operators cost
base and manage their end-to-end VAS ecosystem and help them free up their
precious time to focus on sales, marketing and growing their business. The
major activities on high level activities we take care of for an Operator
include:
Managing a complex value chain such as
that of VAS can drain the Operator’s resources and they risk deviating from
their core competence. MS Managed Services ensures to reduce the Operators cost
base and manage their end-to-end VAS ecosystem and help them free up their
precious time to focus on sales, marketing and growing their business. The
major activities on high level activities we take care of for an Operator
include:
Operational
efficiency in multiple regions:-
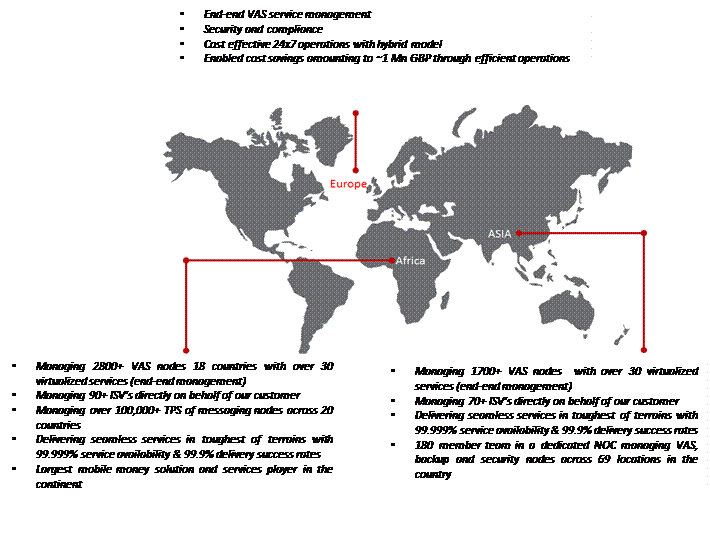
MS
has been awarded by MTN Ghana, Zambia
and Swaziland for the Managed Services operations of different
services. We helped MTN in customer satisfaction levels. MS helped MTN to
retain and enhance competitive edge through transparent business partnerships,
world-class processes, and next generation technology solutions
In
order to meet MTN Ghana’s requirements, MS provides the whole set of MSO. It
includes like Fault Management, Capacity Management, Performance Management,
Accounting & Restoration Management, Back-up Management, Automated Monitoring,
Reporting, Governance etc. which helped operator to fulfill the objectives and
improve to minimize business impact not only for messaging nodes but for other
services as well which are served via messaging nodes, to reduce SRI congestion
, MT delay and improved system KPI’s.
MS
implemented process with ITIL® best practices and helped operator in service
monitoring/day to day operations with best available tools and resources which
helped operator to improve customer satisfaction optimize cost, improved
resource utilization through transformation from manual to automation processes
and implemented DR practices for smooth operations.
And, this rich experience has allowed us to fully understand and MTN policies
and come to know-how, the skills and the solutions need to tackle the
challenges of today and tomorrow.
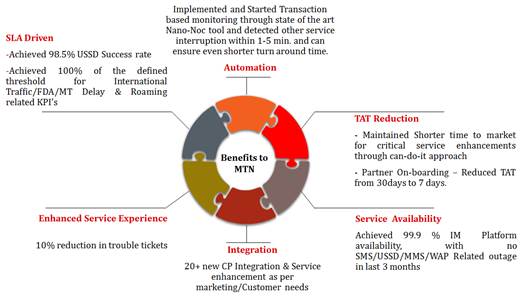 Here
you can review how MS partnership with customer bring in multiple benefits
after MS in GHANA
Here
you can review how MS partnership with customer bring in multiple benefits
after MS in GHANA
MS is pleased to submit its response
to the opportunity of <<Opportunity Name>> and offers
leverage its best solution. We MS can make significant contributions to <operator
Name>overall Objectives as:
MS solution for operator’s objectives
has been designed keeping in mind that solution must be with a wide range of
cost-effective, reliable; supported by tools, professional team those handles the
day-to-day operations, new integration and provides support services to our
customers around the clock.
According to the Request for Proposal
of <Operator
Name>, MS understands the requirements by the following
deliverables:-
MS
offers a set of predefined solutions that can be implemented quickly and
deliver value. Solution is combined with service offering using ITIL® best practices
and the best of breed management tools from our partners wrapped with our service
delivery capability. MS provides industry best practices, Delivery model,
Methodology, proposed tools, Governance model and operational process to build <Operator
Name> objective. MS is able to deliver solutions fast, with high
quality, in a cost-effective manner because of:
The delivery model aims to align
people, process and Tools to deliver MS scope and provide the operator benefits
from improved quality of service and visibility. MS offers a delivery model
which can be customized as per operator requirements.
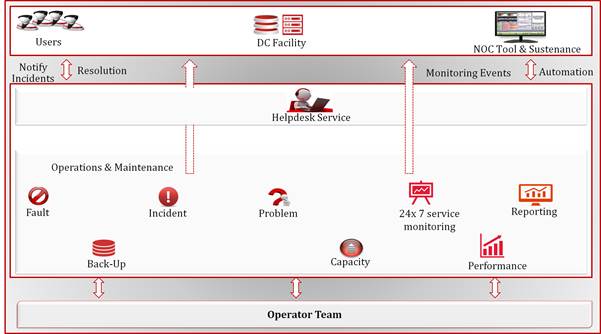 Service will be the Single Point of
contact and would engage the ISV’s via multiple mediums to troubleshoot as well
as create incident and Service request tickets. This team will be an able mix
of efficient and trained Technical service desk personnel, who are well versed
on the tools and processes to coordinate the VAS nodes support requirement.
Service will be the Single Point of
contact and would engage the ISV’s via multiple mediums to troubleshoot as well
as create incident and Service request tickets. This team will be an able mix
of efficient and trained Technical service desk personnel, who are well versed
on the tools and processes to coordinate the VAS nodes support requirement.
Single
point of contacts for all requests coming from Business users and associated
information is maintained and reported in accordance with Service Level
Agreements. This Service Desk will be accessible from all the Operator
locations, e-mail and telephone.
Manual
incidents will be raised by the MS Helpdesk team for infra and Application. The
main services shall include:
·
24x7x365
support.
·
ITIL®
model compliance.
·
Single
Point of Contact via Telephone in English.
·
Logging,
Routing and Tracking of Incidents, Service Requests and Change request to
respective vendor via phone or email.
·
Service
Level reporting against objectives.
·
Circulating
Dashboards.
·
Notification
management.
Service
Components of MS Service Desk:
User Event Management – Perform service desk/customer
relationship management activities for enterprise customers. Provide a unique
contact to the enterprise user regarding the services under scope of the Help
Desk function. Usually to provide support to selected services and to configure
enterprise user services configuration and accounts. To detect any events
related to specific services performance or quality provided to the enterprise
user and to initiate functional escalation of incidents. It will help in
Identification of services or resources (associated to multi users) incident
and escalation to the next level of operations for resolution.
User Incident Management –Perform all activities related to
enterprise user incident resolution. It will be responsible in end-to-end
resolution for enterprise user incident, Identification of infrastructure
(services or resources) incident and escalation to the next level of operations
for resolution.
User Problem Management - Perform all activities related to
enterprise user proactive and reactive problem management. It helps in
Initiation of multi-user (infrastructure) problem management escalation to the
appropriate level of operations (as a result of customer fault trending or
other proactive initiatives).
User Order Handling - To provide an entry point for
enterprise user standard requests (according to SLA reflected on the WLA).
Usually related to service provisioning and enterprise user account
administration
Configuration
Verification -
Perform daily routines for verification of information for new or updated
objects in configuration management database and for verification of
configuration management database of the specific resources or services used to
provide enterprise user support.
·
Providing
quality technical resolution to all SR raised by Call centre for all VAS
services
·
Providing
permanent fix to the SR logged by collaborating with VAS OEM’s.
·
SPOC
for PAN India VAS SR resolution, permanent fix and RCAs.
·
Responsible
for reduction of repeat SR logging by improving quality resolution & RCA /
permanent fixes.
·
Responsible
for generating, tracking and distributing the MIS reports and dashboards as
agreed frequency (daily/weekly/monthly) for all VAS SRs.
·
Coordinating
with Vodafone stake holders for integrating the new VAS Service for SR logging
and resolution.
·
Responsible
for all documentation and SOP’s for VAS SR resolution process
Channels of getting Complaints
MS
will deploy necessary centralized command center team on 24x7 basis consisting
of L1 resources for primarily doing continuous proactive node monitoring,
preventive system health checkups, proactive audits for service configuration, redundancy testing
for LAN/SS7 links/Power with the help of onsite team, Backup restorations
verifications.
MS
provides comprehensive service offerings to help Operators to plan design and
operate their system and maintain ongoing maintenance and support. Service
surveillance helps Operators to achieve the full benefits of this solution
while lowering total cost of ownership.
Network
Monitoring and Surveillance provide:-
·
Around-the-clock
proactive monitoring
·
Performance,
Event, Incident, Problem and Configuration management
·
Guaranteed
service levels (service assurance)
·
Preventive
maintenance
Our Managed
services provide monitoring of:
·
Hardware
·
Server
OS
·
Database
·
Backup
and Storage
·
Security
Level
1(L1) is frontline of support for Incidence management of MS-VAS. L1 mainly
responsible for providing alarm monitoring and L1 support to incidences based
on SOP. L1 trained to do pre-approved standard changes in the system. Some of
the tasks which come under L1 preview as below:-
L2
support team will be responsible for resolving all production issues,
coordinating with product vendors to get Level 3 support when required. They
will be responsible for carrying out changes in production environment in
accordance with the product vendors SOPs. The tasks involved are as follows:
·
Analyze
and resolve incidents escalated from L1 team
·
Provide
Root Cause Analysis in consultation with Product Vendors and take corrective
actions to avoid repeat incidents of same nature.
·
Consultation
with core team for capturing traces (wireshark) analysis on core issues, system
issues and RCA.
·
In
case of failure, perform necessary recovery procedures as per product vendor
guidelines
·
Analyze
capacity utilization and service volume data on regular basis and provide
summary insights to product vendors and Architecture teams.
·
Escalate
issues to L3 teams and coordinate for resolution
·
Coordinate
integration of new services into OAM environment [ NOC tools and MS process
framework ]
·
Develop
and maintain VAS application inventory including the status of warranty and
maintenance contracts with respective suppliers.
·
Problem
management and Knowledge Base Management
·
Implementation
of recommendation given in RCA
·
Configuration
change for pre-approved CRs
·
Perform
TAB for CR
·
Monitoring
performance report
·
Taking
action on performance degradation incidence
·
Backup
Policy review
·
Maintaining
CMDB consistency ( Put Disclaimer Somewhere in DOC for CMDB ,If available )
·
ISV
review
·
Tracking
and take action agreed in ISV review
·
Incidence
analysis
·
Tracking
and take action in Incidence analysis
·
Monitoring
template review and update as required
·
Client
review
·
Tracking
and take action agreed in Client review
·
Take
action on audit results
·
Support
in New node integration template review
·
Taking
handover from ISV after RTP completion
·
Maintain
and review SOP for L1 & L0
·
Create
and maintain Call Flow documents
·
Maintain
deployment architecture of services
·
Monitoring
of Backup success failure Report
MS
onsite operations team will primarily be responsible for hands and eye support
and management of the VAS infrastructure of network VAS nodes. Apart from this
the team would perform Server management, data center hygiene, Audits and
Access control in coordination with the centralized NOC and Operator Local SPOCs.
MS
field service work order fulfillment will be responsible for plan and confirm
Service Activation/Deactivation time with the requestor, complying with the
business rules of scheduled outage times (if applicable), (Re-)configuration of
equipment at site according to established and agreed procedures, perform
end-to-end tests together with the requestor to confirm that service is
active/inactive. Report completion of work and escalate problems as required.
The purpose of Planned Maintenance is to undertake maintenance activities which
are required to be scheduled. Reasons for scheduling such tasks may include:
·
Occasions
where the corrective maintenance activity needs to be scheduled within defined
maintenance windows;
·
compliance
with business rules regarding network outages;
·
specialist
access requirements (eg use of cherry pickers or cranes, road closures etc);
·
lease
restrictions on business hours access;
·
Requirement
to use external resources or hardware etc.
Planned
maintenance may include any other maintenance activities not included in the
Preventive Maintenance plan, as agreed.
Responsible
to plan and confirm Planned Maintenance time with the requestor, complying with
the business rules of scheduled outage times (if applicable), perform
end-to-end tests together with the requestor to confirm that functionality is
restored or established (if applicable), record asset numbers of equipment
received/replaced/installed by Ericsson (or its agents) and escalate problems
as required.
With
following strategic method MS transform day to day related management
responsibilities:-
Corrective Maintenance
Execution - Dispatch
field technicians in the event of an identified or suspected on-site fault,
assist with the fault identification and replacement of identified faulty
unit(s), restart or Power Cycle faulty unit(s), perform tests together with
Incident or Problem Management to confirm that functionality is restored,
record actions in logbooks kept at all sites, report on problems observed
during Corrective Maintenance actions that are outside the scope of current
Corrective maintenance activity. Record asset numbers of equipment
received/replaced/installed by Ericsson (or its agents) during the Corrective
Maintenance process, manage the repair and return process of any equipment in
need of repair as detailed in the specification of Spare Parts Handling, report
completion of the work and escalate problems as required.
Site Information
Management - Update
site access information when changes are discovered through standard field
activities, update site configuration information after equipment/services are
installed/de-installed and update 3rd party provider information such as power
supply authority details, landlord details, security contractor details etc.
Third Party Supervision – MS shall, upon request from
Customer or other "approved requestors", facilitate visits to sites
for the purpose of inspection or other activity by authorized 3rd Party
personnel. Any such visits will be in accordance with agreed and established
security policies for 3rd Party site access and supervision. 3rd Party
supervision procedures are to be detailed in WLA.
Preventive Maintenance
Execution - Perform
routine infrastructure (resources) maintenance activities as requested by
[[Service Function - 2nd Level Operations|2nd Level Operations and defined on
the Preventive Maintenance plan and schedule.
Spare Part Handling - The Spare-part handling service
shall ensure that the inventory of spares required for the Customer’s Network
is managed and maintained as agreed on the SLA, and that the necessary spares
are delivered to site for Corrective, Preventive or Planned Maintenance
actions. Responsible for transportation and storage of equipment, according to
established and agreed procedures, to comply with any agreed and specific
security policies for spare parts storage and delivery. Maintain an agreed
spare-part inventory database (return and management of the returns process of
faulty cards, receiving the replacement card, return of faulty units to
equipment supplier for repair or exchange, reception of repaired units from
equipment supplier), supply spare-parts inventory to the Customer. Responsible
for the administration, storage and management of any documents to accompany
the Equipment, which shall at all times, remain the property of Customer.
Site Access Control - Manage site access in accordance
with agreed and established security policies, maintain a list of authorized
personnel requiring site access for the provisioning of services and other
activities, control and manage the distribution of keys to service personnel
and authorized 3rd parties (according to WLA) and regularly send the authorized
personnel list to the Customer.
Work Order Management
(SPOC Dispatch Function)
- Management of the field technician’s tasks attribution in response to a work
order or customer request.
On-boarding of ISV &
Test Bed Management
MS
will be responsible to do complete end to end testing on test bed platform of
all voice based/USSD /SMSC /Data/Location services before going live to
production platform.
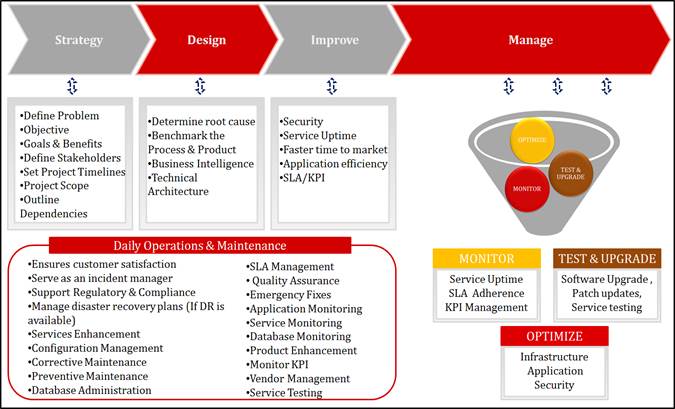 MS approach will be to apply its
proven methodology as “SDIM”
to fulfill <Operator
Name> objective. MS will align to Operator a well-defined
framework and implement best practices to achieve <Operator Name>
requirement.
MS approach will be to apply its
proven methodology as “SDIM”
to fulfill <Operator
Name> objective. MS will align to Operator a well-defined
framework and implement best practices to achieve <Operator Name>
requirement.
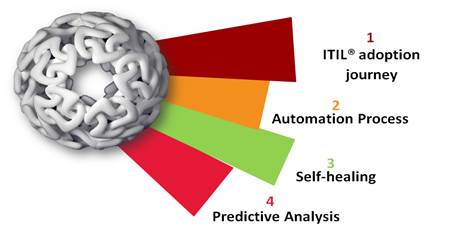
MS
Managed services models based on ITIL®
adoption journey, Automation process, Self-healing and Predictive Analysis which allows you
to scale quickly while controlling capital and operational experience to
deliver customer value more effectively. So you have the right services to fit
your business needs. It helps operators to deal with operations and maintenance
challenges. As a managed services partner, we bring cross-domain expertise and
an in-depth understanding of the challenges and opportunities facing operators
today. It’s all about creating the best experience – for you, your staff, and
your customers.”
Managed
Services of MS have “Three Elements” which are the best practices and they have
been used to improve the Service quality for Customers.
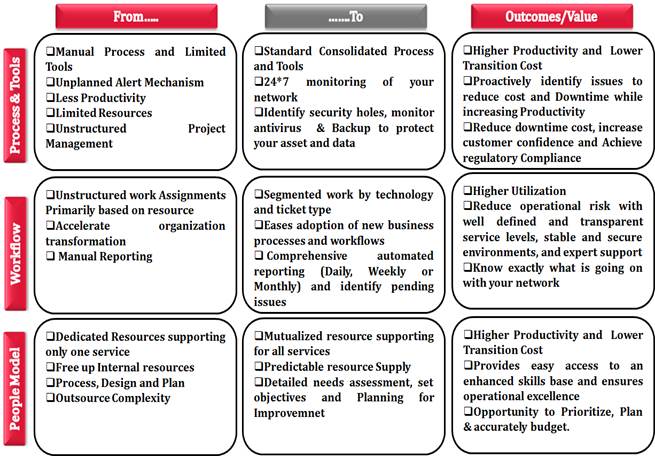 The three areas of focus include
Process & Tools, Workflow and People Model.
The three areas of focus include
Process & Tools, Workflow and People Model.
MS
offer tools to “Modernize processes and fast-track growth”
 In the recent past, Telco operations
were limited to monitor individual nodes of network through available tools and
automate day to day process so today focus has shifted on improving the quality
of services they give. MS will bring tools to accurately measure service and
judge the root causes influencing user perception and establish a system of
indicators, starting with KPI, to KQI and ultimately to perceived QoE. Automation and Predictive analysis are the fundamental value delivered by MS
Managed services. It helps optimize and integrate operational process that
directly supports the delivery of services.
MS solution helps operators in achieving operational automation by
leveraging different tools and adapting best ITIL® practices. A wide range of
standard operation procedures in different technologies or environments will
ensure consistent services delivery. The proposed tools will be as following and to view feature details of
proposed tools refer Standard
Technical Proposal_MS\Annexure A_Tools Solution Overview_Sample.doc
In the recent past, Telco operations
were limited to monitor individual nodes of network through available tools and
automate day to day process so today focus has shifted on improving the quality
of services they give. MS will bring tools to accurately measure service and
judge the root causes influencing user perception and establish a system of
indicators, starting with KPI, to KQI and ultimately to perceived QoE. Automation and Predictive analysis are the fundamental value delivered by MS
Managed services. It helps optimize and integrate operational process that
directly supports the delivery of services.
MS solution helps operators in achieving operational automation by
leveraging different tools and adapting best ITIL® practices. A wide range of
standard operation procedures in different technologies or environments will
ensure consistent services delivery. The proposed tools will be as following and to view feature details of
proposed tools refer Standard
Technical Proposal_MS\Annexure A_Tools Solution Overview_Sample.doc
Note:- <<Tools &
annexure A mentioned in this section need to customize as per operator’s
requirement>>
![]()
 GNOC - A Global Network
Operations Center (GNOC) is a NOC, which operates multiple networks of
different countries in a centralized location.
GNOC - A Global Network
Operations Center (GNOC) is a NOC, which operates multiple networks of
different countries in a centralized location.
GNOC Benefits:- ·
Real time Care ·
Early Detection and hence early
intervention. ·
Improved system Availability and
Performance ·
Local talent agnostic especially for
emerging economies ·
Worry-free operations and
maintenance ·
Significant savings on cost ·
End User Experience Monitoring ·
Significant reduction in Operation
cost for Support system team. COMVIVA GNOC
RADAR
- “RADAR” is new
Capability to diagnose the Service level challenges. It enables auto
detection and diagnoses of problematic areas to measure and improve end
user experience. This is carried out through a
combination of mobile simulation, trend analysis, predictive analysis, and
data analytics. Operators are thus able to detect and fix various
service-related issues before their business is impacted.![]()
RADAR’s Features & Functionalities:-
NanoNOC
– It’s a virtual
monitoring system that emulates the behavior of the mobile user and
measures Quality of service and facilitates in monitoring the quality of
experience. NanoNOC is aimed at providing a common platform to monitor end
to end behavior of services which works over various bearers (SMS, USSD and
HTTP).
![]()

OMEGA - “Omega” is aimed at providing a
common platform to view and download of reports of the various products
hosted, using a single user interface.
![]()

An effective
operations process revolves around the best ITIL® practices of Management which include:
MS
would responsible for achieving the agreed availability SLA. In case of system
failure, MS would work with Operator’s solution providers to provide work around
for the service, so that services to the fullest possible extent can be
restored to meet desired service levels. Operator would enter into agreement
with all its Strategic Partners (SP) and vendors, so that agreed SLAs between MS
and Operator can be provided. It is imperative that Operator shares with MS
agreed SLAs with existing vendors and Strategic Partners. MS and Operator would
jointly identify if any additional agreements are required between Operator and
its VAS solution providers to enable MS meet SLA needs for the managed VAS
services. In order to ensure that agreed
SLAs are met MS would put in place a detailed work flow, which would be on
following lines:
MS
would be responsible for calculating and providing the uptime reports on
monthly/quarterly basis aggregated at various levels.
MS
would be highlighting the various Service availability needs of the network and
invoke corresponding process to get it address.
Objectives
·
Determine
availability requirements in close collaboration with customers.
·
Ensure
the level of availability established for the IT services.
·
Monitor
the availability of the IT services.
·
Propose
improvements in the IT infrastructure and services with a view to increasing
levels of availability.
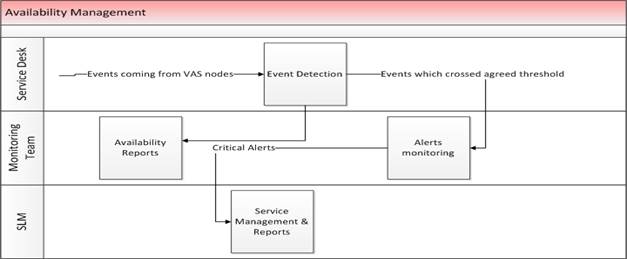 Process
Flow
Process
Flow
An
incident is any event that deviates from the standard and expected operation of
a system. Incident Management is about providing continuity of service to
users/customers by restoring services or providing a work around as quickly as
possible and to minimize any adverse impact on business operations.
The
focus is on quick resolutions allowing users to resume their activities as
quickly as possible. It attempts to ensure high-quality service levels are
maintained and that service availability meets the Customer’s requirements.
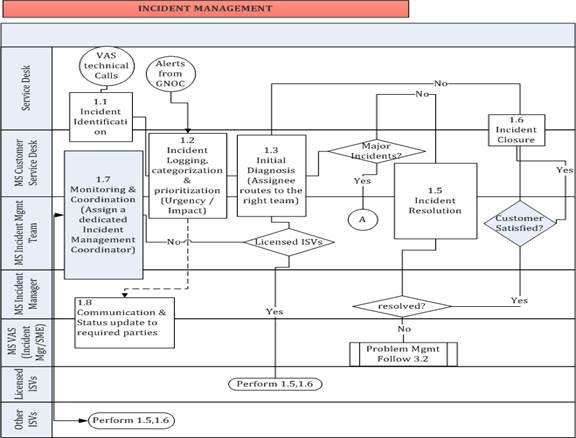 The first step in Incident Management
is acknowledging and accepting ownership of the incident, then documenting
critical information in the incident tracking tool. Incidents associated with
known errors are quickly resolved by applying approved solutions or
workarounds. Incidents associated with an existing or “parent” incident, that
has not yet been resolved, are assigned to the technical support team already
working on that incident’s resolution.
The first step in Incident Management
is acknowledging and accepting ownership of the incident, then documenting
critical information in the incident tracking tool. Incidents associated with
known errors are quickly resolved by applying approved solutions or
workarounds. Incidents associated with an existing or “parent” incident, that
has not yet been resolved, are assigned to the technical support team already
working on that incident’s resolution.
An
incident holds information about the status of a service, a configuration item,
or both. It informs Service Desk users about the reasons behind the status, the
cause analysis for the incident and the actions taken to solve the situation.
Incident Management work Flow
The
diagram below shows a detailed workflow of Incidence Management.
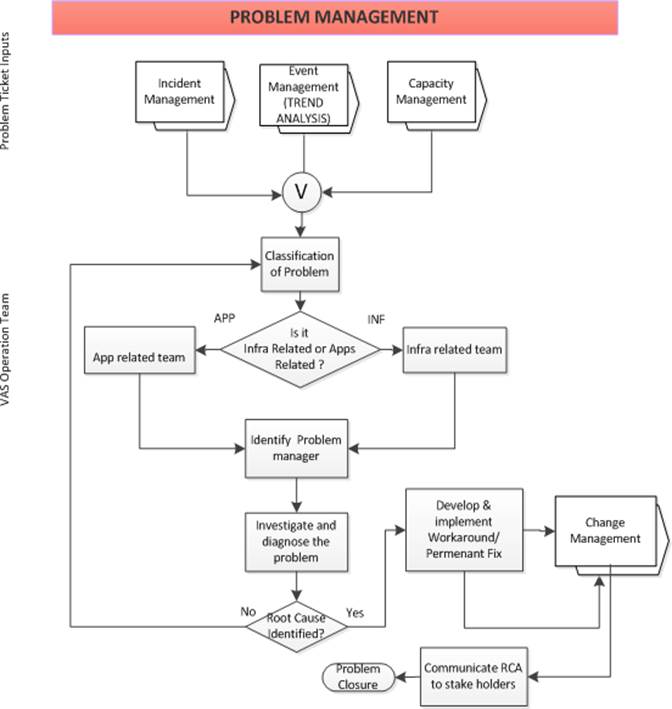
Problem
Management helps minimize the adverse impact of incidents and problems on the
business, caused by errors and majorly prevents the risk of an incident
recurring and prevents new incidents from the same errors or problems. It does
this by determining the underlying cause of a problem and quickly providing
temporary or permanent solutions or approved workarounds. This process involves
initiating and tracking corrective actions, eliminating errors, and preventing
the reoccurrence of associated incidents.
Problem
management also helps improve the Incident Management efficiency and aids
underlined proclamations to:
·
To
establish Root Cause of Problems
·
Provide
a permanent solution or approved workaround quickly and effectively for known
errors
·
Ensure
resources are prioritized to resolve Problems based on business need
·
Proactively
identify and resolve Problems and Known Errors
·
Minimize
Incident occurrences
·
Perform
major Problem reviews and identify lessons learned
MS
manages these procedures throughout the problem life cycle and follows below
procedures Examples of escalation procedures include to:
·
Monitor
the problem
·
Communicate
problem status
·
Update
problem records
·
Update
the known error database
·
Preventive
measures will identify to reduce potential problems based on repeat/trend
incident analysis and proactive management.
Workflow of
Problem Management
Change Management process helps to
provide on-time delivery of changes into the VAS environment and minimize
service interruption. Change Management controls and manages requests to change
the VAS nodes environment or any aspect of VAS services. The process maintains
proper operations between the need for change and potential detrimental impact
of the change while maintaining the integrity of the infrastructure in a
structured manner to meet business requirements.
The aim of the change management
process is to ensure effective handling of changes. All change requests will be assessed,
approved, implemented and reviewed in a controlled manner in accordance with
the Change Control Procedure. A change advisory board (CAB) will be formed with
all the stakeholders as members of this board. The CAB will be responsible for
assessing the impact and approving the changes.
·
Form
a change advisory board (CAB) with representatives of all the stakeholders’
team as members.
·
This
will be jointly arrived during the transition phase.
·
Categorization
of changes based on the impact.
·
Emergency
changes and pre-approved changes would be handled as per the defined process.
·
All
identified changes would be reviewed through CAB for impact analysis and
approval
·
Will
include a comprehensive end-to-end test plan (including clear change acceptance
criteria) notification and escalation lists.
·
Will
include comprehensive contingency plan, including a back-out plan and
procedures (with specific criteria to initiate the execution of the back-out
plan).
·
All
failed changes would be reviewed .( PIR ) Post Implementation review will be
done
·
Preparing
a plan for forward schedule of changes
·
Ensure
that the changes are recorded in CMDB against the CI affected.
·
Generate
monthly change management MIS.
·
Ensure
that all changes are recorded and then evaluated, authorized, prioritized,
planned, implemented, documented and reviewed in a controlled manner.
·
Reduce
number of incident and problems associated with changes.
·
Improve
change perception (reduce the resistance to changes).
·
Maintain
Configuration Management Data Base (CMDB) updated for changes on the network.
|
Chance Criticality |
Description |
|
Critical |
Critical change will have a severe
impact on the customer’s ability to conduct business, and will be a total
addition / loss of server, service or functionality. This will impact a large
proportion of concurrent users at a single/multi site. |
|
Major |
Medium change will have an impact on
the customer’s ability to conduct business, and will be an up-gradation /
degradation of a system or application, with no bypass or immediate recovery
possible. The will impact a group of users or subscribers. |
|
Minor |
Minor change will cause some
performance up-gradation / degradation, loss or inconvenience which has no
impact on the customer’s business operations. The change will have minor
impact one or several users. |
MS also defined Problem severity classes. When a problem is logged, it
will be assigned to a particular class by mutual agreement with MS and Operator
based on the
Severity Table: Response Time,
Restoration Time and Resolution Time.
|
Severity Level |
|||
|
Response Time |
Restoration Time |
Resolution Time |
|
|
Critical |
15
Minutes |
4
Hours |
24
Hour |
|
Major |
30
Minutes |
12
Hours |
48
Hours |
|
Minor |
60
Minutes |
48
Hours |
72
Hours |
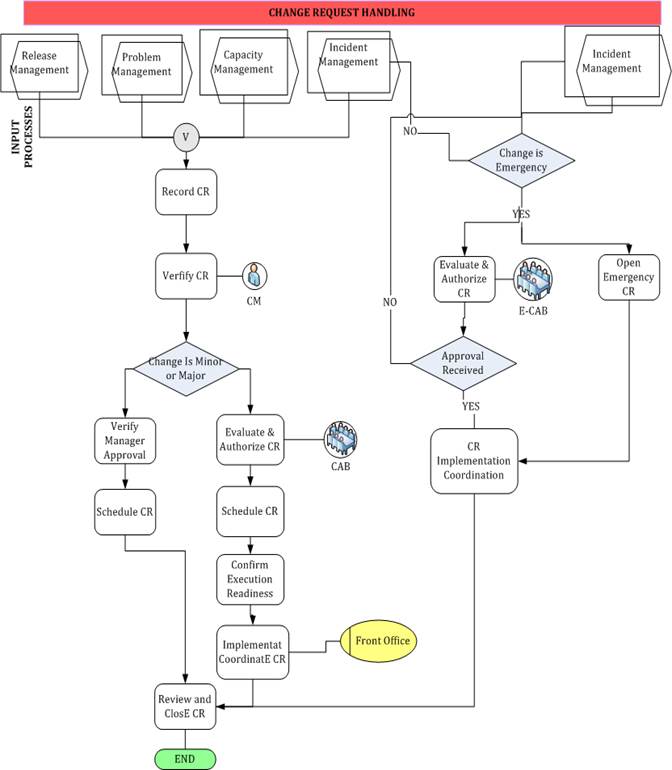 Change Management workflow
Change Management workflow
This
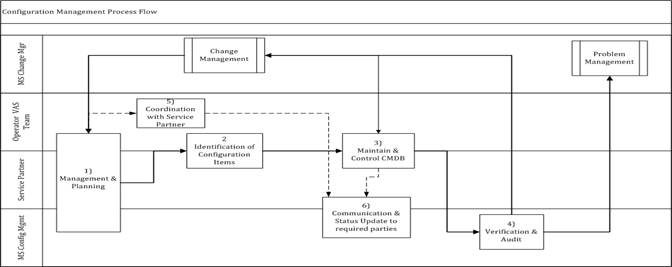
process describes the update and track of Configuration Management changes, and
will define the overall rules, structure and strategies for how a configuration
item is placed under Configuration Management control.
The
Configuration Management process is to provide a logical model of the IT
infrastructure or a service by identifying, controlling, maintaining and
verifying the versions of existing Configuration Items (CIs) in order to
support other processes.
Objectives:
·
Create
policies, standards and processes for configuration management
·
Define
Configuration Management roles and responsibilities
·
Define
consistent CI (Configuration Item) naming conventions
·
Standardize
schedule and procedures for performing Configuration Management activities:
configuration identification, control, status accounting, configuration audit
and verification
Configuration
Management covers the identification, recording and reporting of IT components,
including their versions, constituent components and relationship. Items that
are under the control of Configuration Management include hardware and
software.
Configuration
Management is used to:
·
Account
for appropriate IT assets and configurations
·
Provide
accurate information to support other service management processes
·
Provide
a sound base for Incident, Problem, Change and Release Management
·
Verify
configuration records against the infrastructure and address any exceptions
Release
Management process will ensure that all aspects, both technical and
non-technical, are considered when releasing change into the environment. This
process reduces the cost of releases, minimizes business disruption of
services, and validates releases are correct, consistent, complete, and
compliant with policies from Operator and MS.
Release
Management plans, builds, configures, tests, and implements VAS services into
the environment. Change Management process is actively integrated throughout
the Release Management process to review and approve the release throughout the
release life cycle.
Release
Management is the process that "protects" the live or
production environment. Protection comes in the form of formal procedures
and extensive testing regarding proposed changes to software or hardware within
the production environment.
In
the context of Operator Managed VAS, Release to Production (RTP) process will
be mainly followed in order to integrate the new VAS nodes. VAS O&M team
will release the Release to Production (RTP) process document to all the ISVs
and the team is supposed to ensure the same is being adhered to by all the ISVs
as well as by the VAS O&M team itself.
After
the new nodes are brought into managed VAS infrastructure as per RTP, VAS
O&M team is supposed to follow the Operations Acceptance Test (OAT) and
highlight all the gaps/risks. Only after the gaps/risks are mitigated or the
risk is signed off by the client, the servers are taken in to support.
The
aim of release management is to ensure that all agreed and approved changes are
implemented, controlled and documented in accordance with Operator requirement.
·
Categorize
all releases as per the release policy.
·
Plan
and coordinate to implement the major changes more efficiently.
·
Plan
and or coordinate to rollout of mass deployment of software (mostly patches,
office automation software, packaged applications) and related hardware
·
Will
ensure that any changes / releases are tracked and CMDB updated.
·
Communicate
and manage expectations of the users during the planning and rollout of the
above software and hardware.
·
Ensure
that packaged copies of all approved and latest software as well as the key
configuration files are in a central place (Definitive Software Library - DSL).
·
Generate
monthly MIS for successful and non-successful rollout of software / hardware /
changes.
Performance
Management is fundamental to maintain and monitoring the health of applications
and business critical services. Performance management is both a strategic and
an integrated approach to deliver successful results in organizations by
improving the performance. MS approach helps Operator to provide trending
analysis & reporting to monitor service performance.
Reporting
In
Performance Management we provide reporting tool & MIS reports about
daily, weekly & monthly operations need to be prepared & shared with
client.
Objectives
Frequency
of the reports
The
reports can be monthly, weekly, daily or yearly as per the requirement.
Distribution
of Reports
The
distribution of reports is supported through FTP servers.
Key
Performance Indicator (KPI) is a quantifiable metric that
reflects how well Services are achieving its stated goals and objectives. To
measure and improve performance, Operator needs to track the right KPI.
MS
team focus on KPI benchmarking which is need for continuously measuring
processes and practices against the competitors or those who are recognized as
leaders of the industry with the focus on identifying areas of improvement.
Organizations must perform the complex task of keeping pace with dynamic
environment.
Service KPI’s - KPI’s examine monitored data to
identify trends that help establish typical usage and discover opportunities to
better use system resources or improve performance of a particular service.
Below are the sample KPI’s of different services where MS help to monitor performance
of premium services.
Below
list is generic and will be customized according to the specific service to be
audited and data available.
|
Service |
KPI’s |
|
SMSC |
MO Total |
|
MO Success Ratio |
|
|
MT Success Ratio |
|
|
AO Success Ratio |
|
|
FDA rate |
|
|
Service
Accessibility Time (%) |
|
|
SRI & FSM response
time |
|
|
USSD |
User Request to
Response on screen latency |
|
Application to User
Screen latency |
|
|
USSD Gateway to 3rd
party latency over SMPP |
|
|
USSD Gateway to 3rd
party latency over HTTP |
|
|
Service Access Time
(sec) |
|
|
USSD content error
(%) |
|
|
USSD response
failure (%) |
|
|
Signaling link load |
|
|
SMPP Submit_SM
Success Rate |
|
|
SMPP Deliver_SM
Success Rate |
|
|
MO/MT Success rate |
|
|
IVR |
Call Traffic per E1 |
|
Cut Off Call Ratio
(%) |
|
|
SC wise Utilization |
|
|
Number of Calls per
Subscriber |
|
|
Average Call
Duration |
|
|
Platform uptime |
|
|
Billing &
Charging accuracy |
|
|
Reporting Accuracy |
|
|
Mobile
Money |
Utilization report
of each Banks by per Server |
|
SMSC & USSD TPS Utilization
tracking |
|
|
Service Uptime |
|
|
Service delivery
success rate |
|
|
Service failure rate
with error message details |
|
|
Service delivery
Success & Failure Ratio |
|
|
No. of transaction
received on system |
|
|
Count of Failed
transaction |
|
|
DB Utilization
report |
|
|
TPS Capacity |
|
|
% of calls escalated
at backend |
|
|
PCRF |
Packet Loss % |
|
Delay Latency (sec) |
|
|
Point of Interconnection
(POI) Congestion |
|
|
CPU Utilization (%) |
|
|
Memory Utilization
(%) |
|
|
Space used on Disk
(%) |
|
|
No. of Protocol
Error Sent |
MS
team will do the proactive monitoring of VAS infrastructure via NOC tools;
however team will use manual methods where ever the same could not be done via
NOC tools.
Team
will be responsible to raise/invoke required process / alarm in case of any
deviations noticed. Team will coordinate with all stake holders to fix the
incident / deviation till closure.
Performance
monitoring of Hardware, software, (OS/DB/Application) and services (including
NICs, SS7 and media interface cards etc). Generation of alerts (Mail, SMS)
remote monitoring and escalation in case of hardware, software, application,
database etc alarms as per agreed escalation matrix. Synthetic monitoring of
services using tool including reporting in real time with correlation and
locating exact problematic leg of the service flow.
Using
data from the Configuration Management Database (CMDB) to indicate any
particular configuration items that are experiencing recurring incidents.
·
The
number of incidents logged.
Ø
These
can be broken down by the following:
Ø
Number
of incidents per priority, impact, urgency
Ø
Number
of incidents per type and category
Ø
Number
of incidents per person (i.e. top ten incidents per user)
Ø
Number
of incidents per configuration item type (i.e. top ten infrastructure
incidents)
Ø
Number
of incidents per service
Ø
Number
of incidents per business/organizational area
·
The
average time to achieve incident resolution. This can be broken down by the
following:
Ø
Type
Ø
Category
Ø
Priority
Ø
Impact
Ø
urgency
Ø
Service
·
The
percentage of incidents handled within the agreed Service Level Agreements for
that type of incident or configuration item.
·
The
average cost per incident.
·
The
percentage of incidents resolved at first line support that meets the Service
Level Agreement.
·
The
percentage of Incidents resolved by group:
Ø
Service
desk
Ø
Tier
2 support
Ø
Tier
3 support
·
External
suppliers the percentage of incidents assigned more than twice.
·
The
number or percentage of major incidents.
·
The
size of the backlog of unresolved incidents.
·
Breakdown
of incidents by time of day, to help pinpoint peaks and ensure matching of
resources.
·
Breakdown
of incidents at each stage of the process (e.g. logged, work in progress,
closed etc.).
·
Number
and percentage of incidents incorrectly assigned. Number and percentage of
Incidents incorrectly categorized.
·
Number
of incidents handled by each incident model.
·
Number
and percentage of incidents resolved remotely, without the need for a visit.
Number and type of reoccurring incidents.
![]()
Storing,
restoring and recovering data are key Storage Management operational activities
surrounding one of the most important business assets, ensuring that data is
stored properly and available for both restore and recovery, according to
business requirements.
Data
should be classified according to type and a strategy should be developed to
ensure that backup, restore, and recovery operations can be performed to
fulfill business requirements and service level objectives. This section
describes the various definitions that are used to carry out the Data Store,
Restore and Recovery Operations activities. A very clear strategy must be
written and followed in order to shorten the time it takes to store, restore
and recover important business data. Although such a strategy addresses backup,
restore and data recovery operations, it is most commonly referred to simply as
the “Backup Strategy”.
Objectives
·
Preventive
maintenance through backup.
·
Trouble
ticketing for backup & restore process
·
Ownership
roles & responsibilities
·
Data
backup process
·
Data
backup types
·
Data
backup requirements
·
Data
backup Frequency
·
Data
backup Testing
·
Offsite
Storage
VAS
Backup policy to be determined by MS team in conjunction with business partners
compliance leads & IT Infrastructure. Team need to ensure implementation of
VAS backup policy & day to day management of technical environment used for
backups.
![]()
Security Management
MS
will manage Operator’s – Value Added Service (VAS) Node Infrastructures and
Security Governance Services in accordance with Operator’s Information Security
Policies. MS will continue to provide existing Infrastructure Security Services
along with implementing new security solution caters to RFP requirement.
Objective:-
·
Comply to security and possible
additional Customer and/or legal requirements.
·
Minimize security incidents and
escalations.
·
Secure that information is available
and usable when required, and the systems that provide it can appropriately
resist attacks and recover from or prevent failures (availability).
·
Secure that information is observed by
or disclosed to only those who have a right to know (confidentiality).
·
Secure that information is complete,
accurate and protected against unauthorized modification (integrity).
The security services activities
covered broadly in the areas of:-
Access Control
MS will carry out the Access Control
for the in scope infrastructure devices and the controls/guidelines will be
deployed on the device & user access level as per industry best practices
and Operators guidelines.
Vulnerability Assessment and Management
A vulnerability assessment is the process
of identifying, quantifying, and prioritizing (or ranking) the vulnerabilities
in a system. This provides you with a way to detect and plan to resolve
security problems before someone or something can exploit them. Vulnerability
assessment has many things in common with risk assessment. Assessments are
typically performed according to the following steps:
·
Sort assets and capabilities
(resources) in a system.
·
Assign quantifiable value (or at least
rank order) and importance to those resources
·
Identify the vulnerabilities or
potential threats to each resource
·
Mitigate or eliminate the most serious
vulnerabilities for the most valuable resources
Vulnerability assessment consists of
detailed analysis of vulnerabilities present in the VAS servers, applications,
databases and VAS network devices for revealing un-secure open protocols &
services, which can be exploited by external world and the internal compromise.
Security Incident Management
As a part of Security Incident
Management, MS will monitor the VAS environment for any security breaches,
threats, attacks and malicious activities subjected to the availability of
required infrastructure. The security devices (firewall, IDS, perimeter access
devices) and IT assets will be monitored for any abnormalities and alerts.
Common sources through which an event gets identified are from security device
alerts, logs, audit trails, proactive measures (VA etc) and people.
Patch Management
Patches provide a means to update
software without having to upgrade to a new operating system or application
version. Patches are used to repair defects and to add or change software
features. As with most software environments, patches are part of routine
administration for any System Environment. And, As part of the security
operations, MS team will be responsible for managing the patch management for
the applicable Operating Systems in the VAS infra.
While MS is directly responsible for
installing the patches etc, it will also coordinate with ISVs to get these
patches implemented and track/report the compliance levels to all the stake
holders.
MS will be responsible for applying the
patching in to One-Time VAS Nodes (L2 services nodes) after due diligence with
respective ISV. In case of revenue
sharing nodes, ISV will be responsible for the patching activity. MS O&M
Team will carry out Patch management using HP Open View, CAE tool (for Linux
& Windows Servers) deployed at Operator or manually. Any patch update will
be initiated through the change management as part of ITIL operations.
Anti Virus Management
The Malware software programs like
viruses, worms, Trojans etc. can cause considerable damage to information &
IT assets of an organization. Malware Code Management process will provide a
proper framework of safeguards and, procedures to control this severe threat.
The malware code management activity
includes the following:
·
Detect and manage malware related
incidents, issues and alerts
·
Ensure the anti-malware server update
the Malware signature timely for subsequent updating to systems
Strong Authentication
Strong authentication is also called
Two-factor authentication. It is defined as two out of the following three
proofs:-
·
Something known, like a password,
·
Something possessed, like your ATM
card, or
·
Something unique about your appearance
or person, like a fingerprint
When information is particularly
sensitive or vulnerable, using a password alone may not be enough protection. A
stronger means of authentication, something that’s harder to compromise is
necessary.
RFP requirement states that, VAS
vendors / ISV, who require access to VAS Network from Internet, will be
required using Two Factor Authentication Solution. This 2FA functionality
achieved using the RSA Authentication Manager and RSA SecureID tokens
infrastructure that are deployed in Operator VAS environment and providing VPN
access to ISV’s.
System Hardening
Hardening is usually the process
of securing a system by reducing its surface of vulnerability. A system has a
larger vulnerability surface the more that it does; in principle a
single-function system is more secure than a multipurpose one. Reducing
available vectors of attack typically includes the removal of unnecessary
software, unnecessary usernames or logins and the disabling or
removal of unnecessary services.
MS will implement baseline hardening
controls for Operating systems. The hardening scope includes for all Wintel and
UNIX nodes. Any new asset, which will be
deployed in the VAS network, will be hardened as per the defined processes.
Monitoring
MS Security O&M team will monitor
the system generated logs periodically for the Servers & Network security
devices. In event of any issues, alerts, appropriate actions will be taken to
safeguard the network.
Security operations& management
team shall pool logs from information systems to a central log management
systems. These logs shall be analyzed for various security incidents and
events.
In order to meet the RFP requirement of
Log monitoring, MS propose to deploy Centralized Log Management Solution using
HP Arc Sight Loggers in VAS environment. For further details,
Asset Management activity involves
maintains the inventory of the in scope Assets. The inventory of the in scope
assets will be managed by MS team using the DDMi inventory management tool and
with the Support of onsite engineer. The
onsite engineer does Quarterly physical verification of all the in scope VAS
Nodes. Partner team also performs quarterly asset verification with the ISV’s
and any changes in updated in the CMDB.
All the new nodes deployed in the MS
VAS Infra under MS scope will be captured in the Asset Inventory. The Asset
Inventory database will be updated on a regular basis.
The DDMi (Discovery and Dependency
Mapping) has been implemented which
helps in updating some of the fields defined as dynamic in the CMDB
automatically, by which the accuracy of the CMDB can be maintained to the
maximum possible extent. However, the fields that are static in nature need to
be updated manually with a proper change control.
Changes to the CMDB can come from:-
·
Release management - Addition of new CIs (Node Commission)
·
Change Management – Changes to CIs existing in the CMDB
·
Node Decommission Process – Removal of
CIs ; again supported by Change management
MS will be responsible for maintaining
inventory of assets on an ongoing basis. The tasks involved are as follows:-
·
IP addresses of all servers
·
Description of each node, service
·
H/W details: server make, model, serial
number, warranty details
·
OS details and version
·
Database details
·
Application details
·
AMC status of hardware/OS / database/
application
·
License details for the OS, database,
third party products
·
Installed location, Primary downtime
& secondary downtime in case of outages
·
Password availability for Operator’s
owned nodes
·
Telco Details : Point code ,SS7
·
Labeling & Tagging of new node
·
Quarterly CMDB Audit
with ISV
·
Half-yearly CMDB audit with onsite
·
MS will provide Asset Owner, Custodian , User and CIA rating
of the assets
Capacity
Management & Performance Management
Asset Management activity involves
maintains the inventory of the in scope Assets. The inventory of the in scope
assets will be managed by MS team using the DDMi inventory management tool and
with the Support of onsite engineer. The
onsite engineer does Quarterly physical verification of all the in scope VAS
Nodes. Partner team also performs quarterly asset verification with the ISV’s
and any changes in updated in the CMDB.
All the new nodes deployed in the MS
VAS Infra under MS scope will be captured in the Asset Inventory. The Asset
Inventory database will be updated on a regular basis.
The DDMi (Discovery and Dependency
Mapping) has been implemented which
helps in updating some of the fields defined as dynamic in the CMDB
automatically, by which the accuracy of the CMDB can be maintained to the
maximum possible extent. However, the fields that are static in nature need to
be updated manually with a proper change control.
Changes to the CMDB can come from
·
Release management - Addition of new CIs (Node Commission)
·
Change Management – Changes to CIs existing in the CMDB
·
Node Decommission Process – Removal of
CIs ; again supported by Change management
MS will be responsible for maintaining
inventory of assets on an ongoing basis. The tasks involved are as follows:-
·
IP addresses of all servers
·
Description of each node, service
·
H/W details: server make, model, serial
number, warranty details
·
OS details and version
·
Database details
·
Application details
·
AMC status of hardware/OS / database/
application
·
License details for the OS, database,
and third party products
·
Installed location, Primary downtime
& secondary downtime in case of outages
·
Password availability for Operator’s
owned nodes
·
Telco Details : Point code ,SS7
·
Labeling & Tagging of new node
·
Quarterly CMDB Audit
with ISV
·
Half-yearly CMDB audit with onsite
·
MS will provide Asset Owner, Custodian , User and CIA rating
of the assets
MS Security Policy Methodology
![]() MS team must look the following
methodology to manage security practices on different services.
MS team must look the following
methodology to manage security practices on different services.
Knowledge
Management is a tool backed by the data base which qualifies to improve the
decision making for the management and ensures reliable and secure information
and data is available throughout the service lifecycle. The main motive behind
Knowledge Management is to ensure right information is provided at the right
time to enable informed and precise decision.
The
Objective of Knowledge Management includes:-
·
Enabling
team to be more efficient and showcase better quality of service with increased
customer satisfaction along with reduced cost of service.
·
Providing
clear and common understanding to the team about the value their services
provide and the methods in which benefits are realized from its use.
·
Ensuring
the team have enough information at a given time and location.
Information
in form of data is stored in traditional database, like a CMDB, whereas
information can be found in systems as the Configuration Management System
(CMS). Knowledge is stored in the Service Knowledge Management System.
Our
well-evolved Service roll out methodology involves various stakeholders who
enable program management with external vendors and covers all phases of the
Service integration & migration from the stage of Scope closure,
Configuration, testing & go-live.
Service integration is a methodology to manage multiple service
suppliers of different service providers and integrate them in order to provide
single business facing service provider. It focuses at faultlessly
integrate interdependent services from numerous internal and external service
providers into end-to-end services in order to meet business requirements.
Our
strong program and project management skills ensure cost-effective service
rollouts, which are also faster-to-market and 'Right First Time' in the matter
rollout.
Below
are the finest operative approaches to overcome key challenges:
·
Manage
Service Integration Governance
·
Manage
Tools and Information
·
Manage
Providers and Contracts
·
Manage
End-to-end Services
![]() And, Strategy Steps to be followed as:
And, Strategy Steps to be followed as:
Activities
·
Understanding
Deployed Solutions
·
Understanding
current integration channels and interfaces
·
Understanding
current deployed features for all channels
·
Planning
Consolidation and Transformation activities
·
Planning
Migration strategy
·
Implementation
of Solution
·
Configurationally
changes along with service provider
·
Integration
of services
·
Internal
Testing/User Acceptance Testing
·
Phase
wise migration of different Services
·
Managing
operation and Maintenance of deployed platform within defined SLA
·
Ensuring
Quality of services
Approach
We provide accurate
Services by well outlined delivery plan to complete the migration and to ensure
absolute transparency & accountability. In addition, Our Migration approach
is dynamic and is customized based model as following:
![]()
Optimally develop, manage and control vendor contracts,
relationships and performance for the efficient delivery of contracted products
and services.
Objectives
·
Operator
will be responsible for vendor selection for various VAS offerings.
·
MS
MS will be consulted to ensure compliance on aspects such as security,
integration etc.
·
On
a day to day basis, the partner will be responsible for directly interacting as
well as troubleshooting along with other strategic / application partners of Operator.
·
This
is required to own and manage the end-to-end service uptime and associated SLAs
for all the services that fall under the purview of the managed services
agreement.
The purpose of
transition planning is to layout the tasks and activities that need to take
place to efficiently deliver project to <Operator Name>.
![]() The transition plan is used in conjunction with the Project
Charter and to review complete details of project plan go to the section Annexure E_Project Plan.xlsx
The transition plan is used in conjunction with the Project
Charter and to review complete details of project plan go to the section Annexure E_Project Plan.xlsx
Programme
Governance with Operator
![]()
Governance
framework is a conceptual structure that enables different business objects to
be framed and treated homogeneously. It can be defined as a set of concepts
used to solve a problem in a specific domain. Effective and timely measures
aimed at addressing these top management concerns need to be promoted by the
governance layer of an enterprise. Hence, boards and executive management need
to extend governance, already exercised over the enterprise, to IT by way of an
effective IT governance framework that addresses strategic alignment,
performance measurement, risk management, value delivery and resource
management.
The
objectives of the governance structure and process are to accomplish and
direct:
·
Effective
implementation of the agreement including without limitation the establishment
of a process for communication, escalation and planning (i.e. people,
processes, business objectives, functions) associated with the agreement
·
Development
of the organizational relationship between Operator and its partners to
facilitate MSP's (managed service partners) achievement of the agreed service
levels and other obligations, as defined in the agreement
·
Effective,
fair and expeditious process for dispute resolution, including without limitation any
disputes relating to the performance of MSPs
·
The
governance structure and process are intended to facilitate effective
communication between the parties such that:
Ø An effective relationship management
process exists and is followed to avoid misunderstandings and foster good
communication, decision making, and dispute resolution process
Ø The agreement continues to provide
value and innovations to Operator’s throughout the term in accordance with the
terms and conditions of the agreement
Ø
An
effective process for resolution of disputes relating to qualification of
changes under the agreed types of changes. For example, any exceptional change
not agreed between parties, will follow the governance process for resolution
Issue
resolution structure
The
governance of the agreement will be exercised through the Top Executive
Steering Group (TESG), Executive Steering Group (ESG), Functional Steering
Group (FSG), Joint Steering Group (JSG) and the Programme Management Team
(PMT), as described below.
The
members of each group will communicate in principle with the members of the
other Party's group at the same level in the governance structure.
·
TESG
(Top Executive Steering Group) - To derive synergies and cross linkages between
regions, monitor strategic programs agreed between the Parties and act as an
escalation point for resolution of exception cases
·
ESG
(Executive Steering Group) - To provide executive level review and resolution
of disputes relating to the overall relationship between partners under the
agreement
·
FSG
(Functional Steering Group) - To provide and monitor strategic direction and
act as an escalation point for resolution of escalated issues
·
JSG
(Joint Steering Group) - To oversee, manage and direct the escalations brought
up by the PMT and make decisions with respect to the issues involving broader
objectives under the agreement
·
PMT
(Program Management Team) - The overall responsibility of achieving the operational
objectives of the escalated issues under the agreement lies with the Program
Management Team (PMT)
Please refer Standard
Technical Proposal_MS\Annexure B_RFP_Compliance_Template.xlsx to view the Compliance
sheet of this RFP.
The purpose
of this section to specify the split of responsibilities between the MS and the
Operator concerning the total Scope of the Contract.
The following
matrix codes are used:
R - Responsible
A – Approve
C
– Consult
I
– Informed
·
Will be kept updated and notified on status of
tasks but need not be consulted.
To view responsibility matrix please go to Standard
Technical Proposal_MS\Annexure C_RACI_Split of Responsibilities_Standard
Template.xlsx
·
It
is assumed that MS Onsite Engineer, Operations Team will be placed at Operator
Premises and Operator will provide communication channels like Calling Facility,
Internet/LAN facility, Printer, Scanners, etc for protecting the computer &
data and on the basis of requirements.
·
VPN
Connectivity to access the system remotely for support purpose will be provided
by Operator’s team.
·
It
is assumed that MS team will be responsible for only technical operations,
which includes planning, operations & maintenance of Nodes.
·
It
is assumed that MS team will ensure hygiene check-up for provided/ in-scope
nodes
·
It
is assumed that Operator will provide infrastructure & tools for security
& backup management
·
It
is assumed that services are running on redundant set-up
·
It
is assumed that Operator will facilitate Operational Level Agreement (OLA) with
all third Parties like application vendors, LAN/WAN management and MS shall
take a lead to get the things in place.
·
It
is assumed that development related to any product will be done by product
provider and adding/removing of new/old codes will be done by Managed service
provider
·
MS
will manage back-up strategy of database, storage management, assist in proper
restoration/ recovery, archive logs as per agreed Scope.
·
It
is assumed that data storage for backup will be provided by Operator
·
It
is assumed that Operator will share the details of existing available tools
like ticketing tool, monitoring tools, Infra tools, alarming tools required or
already available in eco-system.
·
It
is assumed that MS will not be
responsible for outage due to non-availability of geo redundant setup
·
Operator
will freeze the format and frequency to circulate service performance report
& dashboard during scope finalization. Reports frequency & format to
signed and agreed before making live on production setup. Any adhoc reports would be subject to technical feasibility of
reports generation and availability.
·
Prepaid
/ Postpaid SIMs shall be provided by Operator with or without roaming enabled
for service level monitoring and testing.
·
Required
connectivity between GNOC and monitoring centers will be provided by Operator.
·
Any
Change in system or additional service which is not mentioned in scope will be
mutually agreed after commercial negotiation on case to case basis. Operator
would be responsible for sizing, deploying infrastructure as per Telecom
regulation and guidelines. Any violation/inefficiency due to lack of
infrastructure/inadequate sizing would be owned by Operator.
·
It
is assumed that Operator will be responsible for ordering new capacities based
on plans and required capacities for all services to be deployed in advance. If
any activity which require planned downtime to perform system maintenance e.g
(preventive maintenance, system upgrades, etc.) shall be mutually agreed
between MS and Operator, to minimize the impact to business
·
It
is assumed that if any service is available but server/hardware is not working,
it will not be considered as service degradation. Any unplanned downtime caused
due to power failure, network issue, FTP timeout, network Policy issue, fiber
cut, any change in credentials will not be under MS Control.
·
Operator
will provide required credentials to access SMPP/SMTP or any other account for
operations.
·
MS
will responsible to fetch national roaming partners billing and invoicing from
provided system by Operator’s.
·
MS
will be responsible to upload file to the source
·
MS
will responsible to get close the only audit actionable items with suppliers In
case of chronically under capacity nodes, the SLA/KPI will be struck off from
the calculations after raising the capacity issues by MS
·
Change
implementation plan to be approved by CAB and TAB only as per agreed SOW.
·
SLA
for MS will start when ticket is assigned to their respective bin.
·
Any
break fix activity would be strictly out of MS scope. All such break fix
activity will be performed by ISV/OEM partner or AMC vendor and supported by MS
field resource team. All nodes and infrastructure should be running on latest
adequately sized infrastructure. Issues due to inadequate sizing or EOL/EOS
infrastructure would be out of scope for MS.
·
Any
issue arising in the customer's data center will not impact on agreed SLA.
·
In
absence of required spare parts/Hot-Cold standby hardware if outage duration is
increasing then this duration would be excluded from MS-Partner SLA/KPI. Operator’s
would be responsible for making these items available for quick
resolution/restoration
·
Operator
would be responsible to implement redundancy with adequate capacity at all
tiers mentioned below.
Ø
Node
level
Ø
SS7
network and IP network level
Ø
Telco
component at Node level
Ø
Geographical
·
MS
will not be responsible for increase in number of calls/incidents/events due to
Operator SS7/SIGTRAN and IP Network issues
·
Operator
shall provide a test bed for each of the application which has to be replica of
the production environment for any successful patch testing.
·
Security
policies, procedures and guidelines are owned and maintained by Operator only.
·
MS
will support during UAT process. However, overall UAT execution and sign off
with ISV Partner would be Operator’s responsibility.
·
Cabling,
Spare parts management, material and hardware movement
·
Spare
Part Management at DC and warehouse
·
Geo
redundancy setup and DR procedures.
·
Content
procurement will be done by Operator
·
Third
Party Hardware related issue will be sorted out by operator
·
Operator
will be responsible for all third party payments, measurement and reporting.
·
Testing
of core GSM network for major changes to network.
·
Disaster
recovery sites for MS Services
·
Relocation
& migration of hardware/software due to any changes in the system
architecture or data center relocation
·
AMC
for Hardware & Software and L3 Support
·
Office
LAN, Laptop & infrastructure support for MS Services nodes
·
Network,
Power connectivity, LAN/WAN procurement
·
Seating
space, SIM, network & power connectivity will be provided by Operator to
onsite team.
·
Any
additional Infrastructure required for Operations
·
Software
License details to be shared
|
AMC |
Annual
Maintenance Cost |
|
CAB |
Change
Advisory Board |
|
CMDB |
Configuration
Management Data Base |
|
CI |
Configuration
Team |
|
DC |
Data Center |
|
DSC |
Definitive
software Library |
|
DB |
Data Base |
|
DR |
Data
Redundancy |
|
ESG |
Executive
Steering Group |
|
FSG |
Functional
Steering Group |
|
FTP |
File
Transfer Protocol |
|
GNOC |
Global
Network Operation center |
|
ISV |
Independent
Software Vendor |
|
IP |
Internet
Protocol |
|
JSG |
Joint
Steering Group |
|
LAN |
Local Area
Network |
|
MIS |
Management
Information System |
|
MSP |
Managed
Service Provider |
|
OAM |
Operations
and Maintenance |
|
OAT |
Operation
Acceptance Test |
|
OLA |
Operational
Level Agreement |
|
PMT |
Programme
Steering Group |
|
PIR |
Post
Implementation Review |
|
RACI |
Responsible,
Accountable, Consulted, Informed |
|
RTP |
Release To
Production |
|
SLA |
Service
Level Agreement |
|
SP |
Strategic
Partner |
|
SPOC |
Single
Point Of Contact |
|
SMSC |
Short
Message Service Center |
|
SOP |
Standard
Operating Procedure |
|
SMPP |
Short
Message Peer-to-Peer |
|
SMTP |
Simple
Mail transfer Protocol |
|
SOW |
Scope Of
Work |
|
SR |
Service
Request |
|
TAB |
Technical
Advisory Board |
|
TESG |
Top
Executive Steering Group |
|
USSD |
|
|
UAT |
User
Acceptance Testing |
|
VAS |
Value Added
Service |
|
VPN |
Virtual
Private Network |
|
WAN |
Wide Area
Network |